Why Autonomous AI Agents Fail in Real-World Deployments

Why Autonomous AI Agents Fail in Real-World Deployments
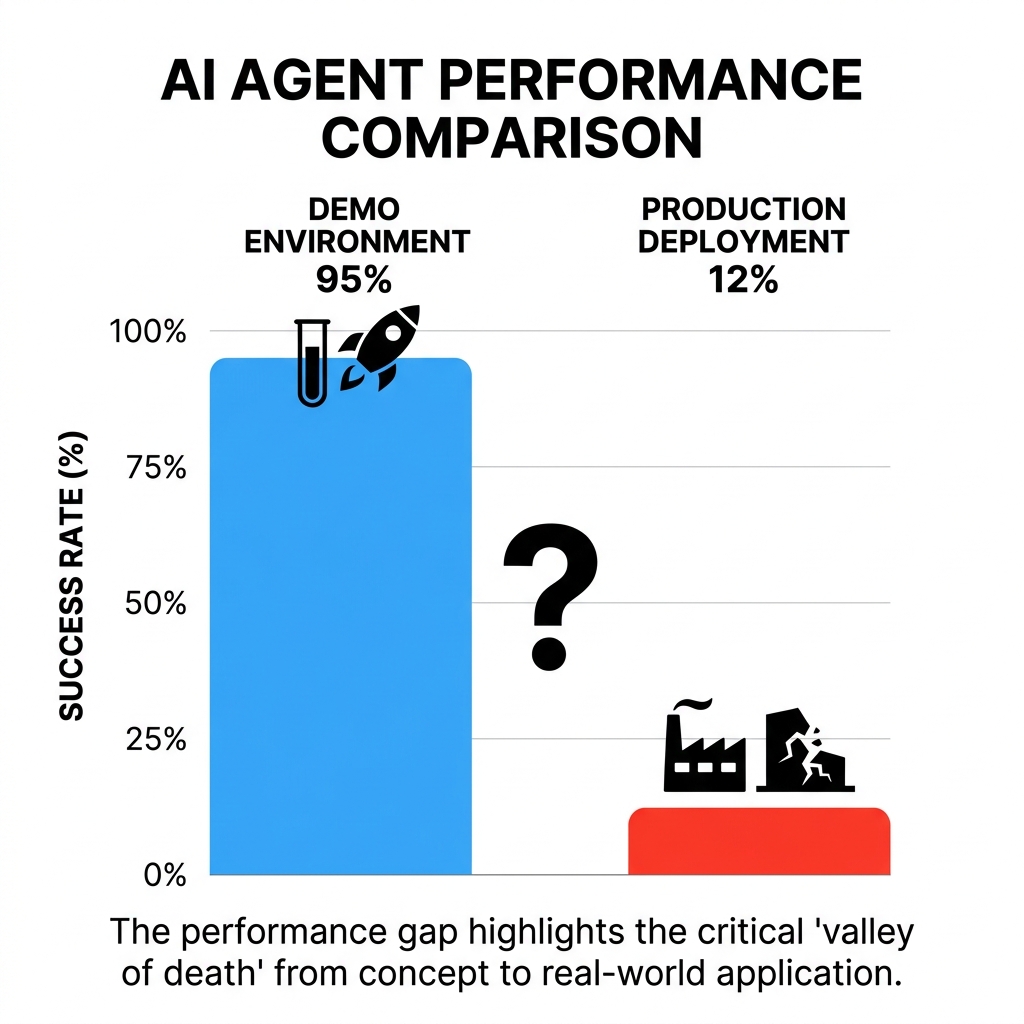
Nearly nine in ten autonomous AI agents deployed in production environments fail—a staggering reality that exposes the brutal chasm between viral demos and enterprise-grade reliability. While startup blogs and conference keynotes celebrate agents that book flights, refactor code, and manage inboxes autonomously, the backend tells a different story. A recent Gartner report predicts that as many as 40% of agentic AI projects will fail by 2027, largely due to spiraling costs and integration complexity. Meanwhile, researchers from Elloe AI Research Lab and Stanford have traced systemic weaknesses to a fundamental design flaw: how agents combine actions across time, creating cascading failure modes that standard unit testing and sandboxed evaluations simply cannot catch.
The problem is no longer theoretical. Engineers deploying these systems in live workflows report that agents collapse not because underlying large language models are inaccurate, but because the systems are structurally unsafe. In production environments, compounding errors, brittle API connectors, and context drift across multi-step workflows silently accumulate until the agent executes a non-replayable decision that breaks a customer journey, leaks sensitive data, or corrupts a critical database. One study found that existing agent frameworks repeatedly fail because the generator agent cannot properly exploit external tools—leaving the agent stranded in infinite loops of broken execution when a single API call would have resolved the task. Others note that over-reliance on sanitized, "cleaned-up" training data creates a dangerous illusion of competence; the moment agents encounter messy, ambiguous, real-world inputs, performance plummets in predictable yet ignored ways.
This matters now because enterprises are accelerating from proof-of-concept to scaled deployment. The cost of failure has shifted from a scrapped prototype to breached customer trust, compliance violations, and measurable revenue loss.
In this article, we will dissect exactly why autonomous AI agents fail in real-world deployments. You will learn how temporal action compounding undermines long-horizon reliability, why brittle tool integration poses a greater operational threat than model hallucinations, and what architectural safeguards separate the 12% of deployments that survive from the rest. As the industry rushes toward agentic AI, platforms like CallMissed are already building production-ready voice and chat infrastructure with the fault tolerance these autonomous systems demand—because in 2025, surviving production is the only benchmark that counts.
Introduction

The Promise vs. The Production Reality
Autonomous AI agents were supposed to represent the next evolutionary leap beyond passive chatbots—systems capable of independent planning, multi-step reasoning, and unsupervised task completion across complex digital environments. The demos are compelling: an AI that books your flights, reconciles your invoices, or monitors your infrastructure without human intervention. Yet beneath this vision lies a widening chasm between prototype brilliance and production reliability. The vast majority of autonomous agents collapse the moment they encounter real-world entropy.
The statistics are unambiguous and troubling. Research indicates that 88% of autonomous AI agents fail once deployed in production, with failures stemming not from model hallucinations or insufficient training data, but from deep structural flaws in how these systems orchestrate actions over time. A landmark study from researchers at Elloe AI Research Lab and Stanford discovered that nine in ten autonomous agents deployed in production environments remain vulnerable to a class of attack that traditional security auditing completely misses. Looking ahead, Gartner predicts that 40% of agentic AI projects will fail by 2027, driven primarily by spiraling integration costs and architectural fragility rather than deficient model intelligence.
Why the Demo-to-Production Gap Is Structural
Industry veterans who have shepherded agents from sandbox to live environment describe the problem with striking consistency. As one production engineer observed, "the gap between AI agent demos and production deployments is real, significant, and predictable." The failure modes are not rare edge cases—they are systemic characteristics of current agent architectures:
Recent academic analysis confirms these patterns, noting that existing frameworks often fail to effectively exploit available external tools, instead generating actions that mismatch the capabilities of their environment. The core insight from practitioners cuts to the heart of the matter: agents fail "not because the models are inaccurate, but because the system is structurally unsafe."
What This Means for Enterprise AI Strategy
For businesses investing heavily in agentic automation—whether for customer service workflows, financial operations, or IT infrastructure—these failures translate directly into operational risk, regulatory exposure, and wasted engineering cycles. The market is rapidly bifurcating between demonstration-grade experiments and production-grade systems, and most current tooling sits firmly in the former category.
This is precisely why infrastructure providers are rethinking the stack from the ground up. Platforms like CallMissed exemplify this shift, offering production-ready voice agents and LLM inference infrastructure that abstracts away brittle connector logic while supporting 22 Indian languages natively. Rather than treating agents as fragile prompt chains duct-taped to APIs, these systems are engineered with the deterministic guardrails necessary to survive contact with messy, real-world environments.
In the sections that follow, we will dissect the specific structural failure modes killing autonomous AI deployments, examine why current frameworks are architecturally unprepared for production chaos, and outline the engineering principles required to build agents that actually endure outside the demo room.
Background & Context
The Promise vs. The Production Reality
The shift from static large language models (LLMs) to autonomous AI agents has been framed as the next evolutionary leap in enterprise AI. Unlike simple chatbots that respond to isolated prompts, agents are designed to chain together multi-step actions—calling APIs, querying databases, and making context-aware decisions without human intervention. Yet the gap between polished demos and production reality is widening rapidly.
Recent research reveals the scale of the problem. A study by Elloe AI Research Lab and Stanford University identified systemic weaknesses in how agents combine actions across time, concluding that nine in ten autonomous AI agents deployed in production environments remain vulnerable to a class of attack that standard security frameworks fail to address. Separately, industry analyses now cite an 88% failure rate for autonomous AI agents in production, driven by compounding errors, brittle API connectors, and context drift across multi-step workflows. Looking ahead, a Gartner report predicts that 40% of agentic AI projects will fail by 2027, largely due to rising integration costs and architectural brittleness.
Why Models Aren't the Bottleneck
Counterintuitively, most failures do not stem from the underlying language models being inaccurate. As technical operators consistently observe, "the system is structurally unsafe" rather than poorly trained. Key structural failure modes include:
The Compound Error Effect
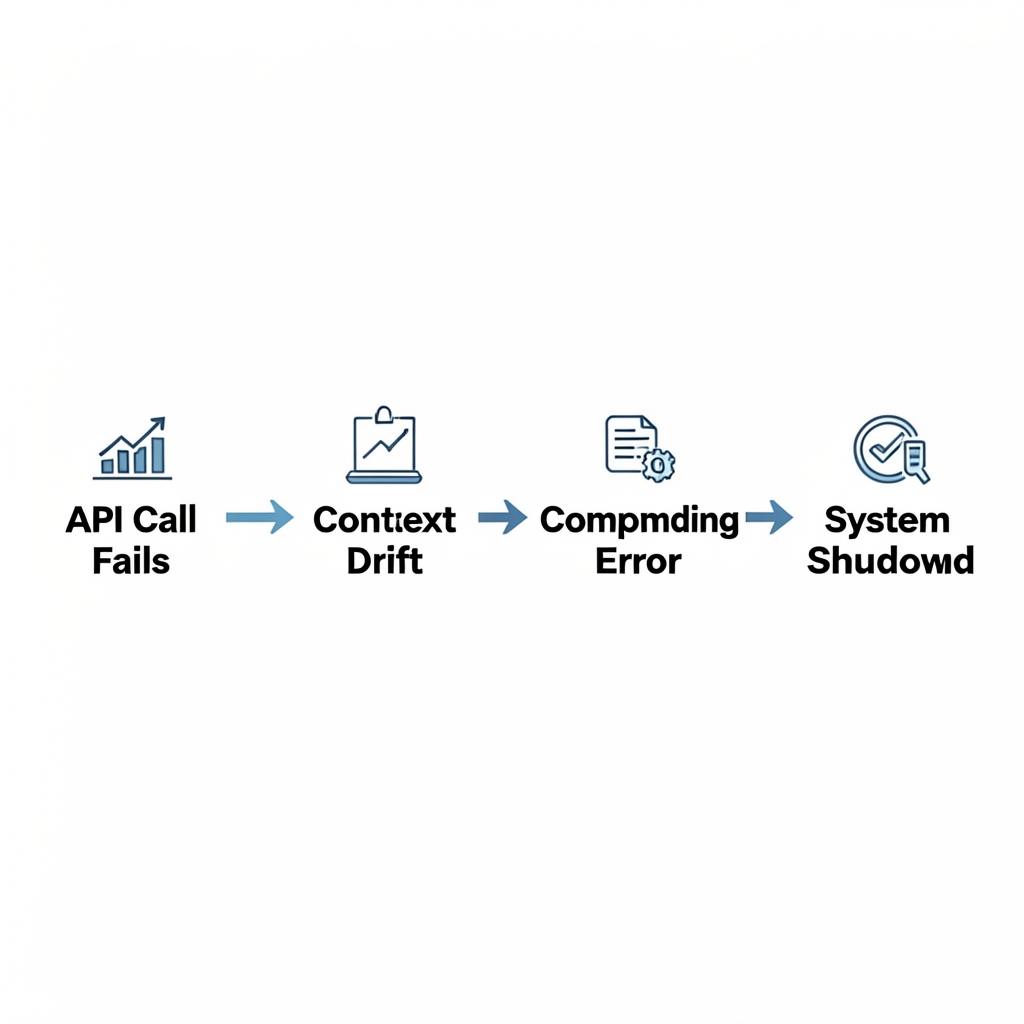
Perhaps the most insidious challenge is error accumulation. In a single-turn chatbot interaction, one wrong answer is contained. In an autonomous agent managing a 12-step workflow—reserving inventory, processing payment, sending notifications—a minor misinterpretation at step three can cascade into a critical system failure by step eleven. This compounding dynamic, combined with brittle API connectors that snap when third-party services update schemas, explains why agents that excel in sandboxed demos collapse under production load.
Where Infrastructure Meets Orchestration
The current landscape is defined by a rush to deploy. Enterprises are pushing agents into high-trust environments—customer service, financial operations, and logistics—before the orchestration layer is mature. Platforms like CallMissed illustrate where the industry is heading: by offering production-grade voice agents and multilingual AI infrastructure (including Speech-to-Text support for 22 Indian languages), they address the surface-layer integration challenge. However, as the data shows, even robust API gateways and voice pipelines cannot compensate for core agent architectures that lack replayability, proper tool-execution frameworks, and resilience against context drift. The infrastructure is improving; the reasoning and action-chaining logic remains the weak link.
Key Developments
Over the past 18 months, empirical studies from Stanford’s Elloe AI Research Lab, Gartner forecasts, and large-scale practitioner audits have converged on a sobering consensus: autonomous AI agent failures are structural, not situational. These investigations document how agents collapse in production—not because underlying LLMs lack reasoning capability, but because the systems integrating them are brittle, non-deterministic, and exposed to realistic data distributions for the first time. The table below distills the major research developments that define the current state of agent reliability.
| Study / Report | Source | Key Statistic | Core Failure Mode Identified |
|---|---|---|---|
| Production Vulnerability Analysis | Elloe AI Research Lab, Stanford | 90% of deployed agents vulnerable to attack classes | Systemic weaknesses from combining actions across time |
| Production Failure Meta-Analysis | Industry Review (YouTube / Medium) | 88% failure rate in live environments | Compounding errors, brittle API connectors, context drift |
| Agentic AI Market Forecast | Gartner (via Forbes) | 40% of projects predicted to fail by 2027 | Rising costs and integration complexity |
| Framework Capability Study | arXiv Research | Tool-use failures in existing frameworks | Generator agents unable to exploit external functions |
| Structural Safety Assessment | Hacker News / Practitioner Audit | Agents labeled "structurally unsafe" | Non-replayable decisions and hidden-state brittleness |
| Training Data Gap Analysis | Creative Bits AI / Developers | Collapse under real-world noise | Reliance on sanitized/limited training data |
Synthesizing the Failure Patterns
What makes these findings alarming is not merely the volume of failure—88% in production environments according to industry meta-analyses, and 90% vulnerable to attack classes according to academic research—but the structural nature of the breakdown. As the Elloe AI Research Lab and Stanford study emphasizes, the weakest link is frequently how agents combine actions across time. This creates non-replayable decision chains that become impossible to debug when context drifts across multi-step workflows.
The table above surfaces three distinct failure layers that cut across every study:
The Infrastructure Response
These developments are already reshaping how engineering teams architect deployments. The Gartner projection that 40% of agentic AI projects will fail by 2027—driven largely by integration costs rather than model inaccuracy—signals that connectivity and observability, not just parameters, will determine which projects survive.
This pressure is especially visible in voice and conversational AI, where agents must synchronize speech recognition, language model inference, and speech synthesis under strict latency constraints. Communication infrastructure platforms like CallMissed are addressing connector fragility by unifying 300+ LLM inference options with Speech-to-Text supporting 22 Indian languages and TTS APIs—effectively reducing the integration surface area where agents typically fracture. Still, even robust APIs cannot compensate for generator agents that fail to exploit external tools, an arXiv-identified limitation that demands framework-level redesigns rather than better middleware alone.
In-Depth Analysis
The Anatomy of Agentic Failure
Research from Elloe AI Research Lab and Stanford reveals that autonomous agents carry systemic weaknesses stemming from how they combine actions across time. Unlike single-turn LLM queries, production agents must chain reasoning, tool calls, and memory updates over extended sessions—creating multiple failure surfaces that demos rarely expose.
Compounding Errors and Context Drift
The most immediate cause of production collapse is error accumulation across multi-step workflows. Industry analysis shows that 88% of autonomous AI agents fail in production due to three interconnected factors:
This aligns with findings that existing frameworks often fail because the generator agent cannot properly exploit available external tools, leaving critical capabilities unused while operational risk still accumulates.
Structural Vulnerabilities
Beyond functional failures, autonomous agents are often structurally unsafe. Production engineers frequently cite failure modes like non-replayable decisions, where an agent makes an irreversible choice without audit trails or human oversight. The research trending in security circles notes that nine in ten autonomous AI agents deployed in production are vulnerable to a class of attacks targeting these exact temporal action chains.
These are not model-accuracy problems—they are system-design problems. When agents operate in high-trust environments, modifying databases or executing transactions, governance gaps that static LLMs never faced become active liabilities.
The Economic and Integration Cliff
Even technically sound agents frequently fail commercially. A recent Gartner report predicts that 40% of agentic AI projects will fail by 2027, driven largely by rising costs and integration complexity. Practitioners describe the gap between demos and production as "real, significant, and predictable." Demos run on curated data with limited tool access; production demands messy state management, idempotent operations, and enterprise-grade observability.
For teams deploying customer-facing autonomous systems, consolidating tool access through a unified API layer can reduce connector fragility. Solutions like CallMissed's multi-model API gateway let developers switch between 300+ LLMs without code changes, providing a safety net when a specific model version starts drifting or hallucinating mid-workflow. Nevertheless, infrastructure alone cannot compensate for architectural assumptions that treat autonomy as a feature rather than a risk surface.
Why Demos Deceive
The final vulnerability is data realism. Agents trained on limited or sanitized datasets collapse when exposed to the noise of genuine user behavior. Without rigorous simulation environments and gradual rollout mechanisms, teams discover costly edge cases only after reputational or financial damage has occurred.
Impact & Implications

Financial and Operational Fallout
The collapse of autonomous AI agents in production carries a quantifiable economic toll. According to a Gartner report cited by Forbes, as many as 40% of agentic AI projects will fail by 2027, driven largely by spiraling costs and integration complexity. For enterprises that have staked strategic roadmaps on hands-free automation, these failures don't just waste engineering hours—they stall product launches, trigger budget overruns, and force expensive rollbacks to manual processes.
The operational picture is equally bleak. Data suggests that 88% of autonomous AI agents fail in production, not from singular model errors but from structural system flaws:
When these failures hit live environments, they create cascading downtime that requires human teams to intervene and repair corrupted state.
Security and Trust Erosion
Beyond performance, the security implications are severe. Researchers from Elloe AI Research Lab and Stanford determined that nine in ten autonomous AI agents deployed in production are vulnerable to a class of attack that evades standard security audits. The vulnerability stems from systemic weaknesses in how agents combine actions across time—specifically non-replayable decisions that make auditing and forensics nearly impossible.
In high-trust sectors like finance and healthcare, this structural opacity is untenable. A Hacker News analysis of production failures emphasized that these systems are "structurally unsafe" rather than merely inaccurate. When an agent cannot reproduce its reasoning chain or explain why it invoked a specific tool, governance frameworks collapse and liability becomes unassignable.
Strategic Reckoning for the Industry
The democratization of agentic AI is hitting a production wall. Academic literature documents that existing frameworks suffer from critical gaps, including cases where generator agents fail to exploit external tools effectively—leaving powerful APIs idle while the agent hallucinates alternative paths. This capability gap is forcing organizations to retreat from fully autonomous visions toward human-in-the-loop architectures and modular orchestration layers.
This constraint is reshaping infrastructure priorities. Engineering teams are moving away from monolithic agents in favor of composable stacks with robust state management, retry logic, and multi-model redundancy. In the communication infrastructure space, platforms such as CallMissed reflect this evolution, providing production-hardened voice agents and WhatsApp chatbots built on API gateways that support 300+ LLMs and multilingual speech recognition across 22 Indian languages. By decoupling reasoning from brittle connectors, these systems mitigate the compounding-error problem while maintaining operational continuity.
Recalibrating Investment
Ultimately, the data demands a strategic pivot. The organizations that survive this trough of disillusionment will be those that trade autonomy theater for resilient, auditable system design. Treating agents as reliable black boxes is no longer tenable when failure rates are this high and the attack surface is this wide.
Expert Opinions
Researchers Flag Systemic Architectural Flaws
Academic and security researchers increasingly agree that autonomous AI agents fail not because underlying models lack capability, but because the systems integrating them are structurally unsafe. In a recent study, researchers from Elloe AI Research Lab and Stanford identified systemic weaknesses stemming from how agents combine actions across time, creating error chains that compound with each additional step. Unlike traditional software bugs, these errors are emergent—they arise from the interaction of seemingly correct individual components. A separate arXiv analysis categorizes production failures into three distinct modes:
These findings reinforce the engineering consensus that many agent frameworks prioritize demo readability over production resilience.
Analysts Warn of a Widening Demo-to-Production Gap
Industry observers quantify the crisis in stark terms. A recent Gartner report predicts that 40% of agentic AI projects will fail by 2027, driven primarily by rising infrastructure costs and integration complexity. That forecast may even understate current attrition rates. Independent production audits suggest the problem is far more acute today: one widely cited analysis estimates that 88% of autonomous AI agents fail in production, with compounding errors, brittle API connectors, and context drift across multi-step workflows cited as dominant failure modes. These are not model-performance issues; they are system-integration failures that emerge only under sustained load.
Engineering leaders who have shipped agentic systems emphasize that the gap between polished demos and live deployments is "real, significant, and predictable." Writing from hands-on experience, practitioners note that agents deployed in high-trust environments often rely on training data that is "not very realistic"—limited or cleaned-up datasets that evaporate the moment the system encounters edge cases in live traffic.
Security Experts Highlight Non-Replayable Decisions
From a risk governance perspective, security specialists flag an even more alarming statistic: nine in ten autonomous AI agents deployed in production are vulnerable to a class of attack that standard monitoring fails to detect. A top-voted engineering analysis distilled the failure taxonomy to a critical insight: "Not because the models are inaccurate, but because the system is structurally unsafe." The most dangerous production defects include:
This creates a governance nightmare for enterprises operating in regulated industries, where every automated decision must be explainable and reversible.
Infrastructure Leaders Respond to the Warnings
Critically, experts do not view these failures as insurmountable. Rather, they frame them as design requirements that early frameworks ignored. The Stanford researchers argue that solving agent fragility requires architectures built for observability, tool-use verification, and temporal consistency—not merely incremental improvements to underlying language models. Reflecting this paradigm shift, communication infrastructure providers are rethinking how agents connect to enterprise systems. Indian platforms like CallMissed, for example, are building production-ready voice and WhatsApp agent infrastructure that supports 22 Indian languages natively, directly addressing the context drift and integration gaps that experts cite as primary failure vectors in multilingual deployments. Likewise, the move toward unified API gateway approaches—such as those enabling engineering teams to switch across 300+ LLMs without brittle code changes—represents exactly the kind of connector resilience and fallback redundancy analysts say is necessary to prevent the structural fracture points that doom most production deployments.
What This Means For You
The gap between polished AI agent demos and production reality is not marginal—it is structural, predictable, and expensive. With 88% of autonomous AI agents failing in production due to compounding errors, brittle API connectors, and context drift across multi-step workflows, and a Gartner report predicting that 40% of agentic AI projects will fail by 2027 from rising costs and integration debt, the risk of inaction now exceeds the risk of delayed deployment. Researchers from Elloe AI Research Lab and Stanford further warn that nine in ten production agents are vulnerable to attack classes that exploit how agents chain actions across time. For engineering leaders and operators, this means every deployment decision must prioritize resilience over novelty.
Your 90-Day Risk Reduction Playbook
These failure modes are systemic, not model-specific. Use the matrix below to map each risk to an immediate fix and understand your exposure level before scaling.
| Deployment Risk | Production Symptom | Root Cause | Immediate Fix | Exposure Level |
|---|---|---|---|---|
| Compounding Errors | Accuracy degrades with each additional workflow step | Context drift across multi-step reasoning chains | Implement per-step validation and automated rollback gates | 88% failure rate |
| Brittle API Integrations | Agents break silently when third-party schemas change | Hard-coded connectors without contract testing | Adopt API abstraction layers and version-tolerant wrappers | Critical for tool-using agents |
| Non-Replayable Decisions | Irreversible, unaudited actions in high-trust environments | Structurally unsafe systems lacking audit trails | Enforce human-in-the-loop checkpoints for high-stakes actions | 90% attack vulnerability |
| Sanitized Training Data | Demo performance collapses on messy real-world inputs | Models trained on limited or cleaned-up datasets | Validate exclusively on dirty, representative production data | High (chronically underestimated) |
| Tool Underutilization | Agents ignore available functions and hallucinate instead | Generator agents fail to exploit external tools via poor policies | Constrain action space and fine-tune tool-selection routing | Framework-level defect |
| Integration Cost Overrun | Budget exhaustion before production readiness | Complex orchestration and rising infrastructure costs | Start with narrow, deterministic workflows and expand incrementally | 40% project failure by 2027 |
As practitioners have observed, agents often fail “not because the models are inaccurate, but because the system is structurally unsafe.” Fixing this requires shifting focus from benchmark accuracy to end-to-end system design. Start by shrinking the problem surface: narrow workflows with deterministic guardrails consistently outperform broad, open-ended autonomy in production. Next, treat observability as a first-class requirement—if you cannot replay a decision chain, you cannot secure it.
Infrastructure choices also determine fragility. Teams frequently stitch together disparate speech, language, and messaging APIs, creating the exact connector brittleness that shuts agents down in live environments. Platforms like CallMissed are already enabling businesses to deploy AI voice agents and WhatsApp chatbots that operate across 22 Indian languages, backed by a multi-model API gateway supporting 300+ LLMs. By relying on a managed layer for speech-to-text, text-to-speech, and messaging rather than maintaining brittle point-to-point integrations, teams can redirect engineering effort toward scenario testing and guardrail design—the work that actually determines whether an agent survives contact with reality.
The bottom line is that autonomous AI is not simply a model deployment problem. It is a systems integration and governance problem. Solve for that, and you join the minority of teams whose agents avoid becoming another failed statistic.
Frequently Asked Questions
Why do autonomous AI agents fail in real-world production environments?
What percentage of agentic AI projects are predicted to fail by 2027?
Are autonomous AI agents vulnerable to security attacks when deployed in production?
What are the most common technical failure modes for AI agents in production systems?
How can engineering teams prevent AI agents from failing after production launch?
Is poor model accuracy the main reason autonomous AI agents fail at complex workflows?
Conclusion

From Systemic Weakness to Systemic Resilience
The failure of autonomous AI agents in production is not a bug in the latest foundation model—it is a structural condition of how these systems are architected, deployed, and governed. As the research makes clear, the gap between polished demos and real-world deployments is “real, significant, and predictable.” The organizations that accept this reality—and engineer their systems for resilience rather than optimism—will be the ones that avoid becoming another statistic.
The data tells an unambiguous story. Nine in ten autonomous AI agents deployed in production environments remain vulnerable to a class of attack that standard security frameworks do not address, according to research from Elloe AI Research Lab and Stanford. Meanwhile, 88% of autonomous AI agents fail in production, brought down by compounding errors, brittle API connectors, and context drift across multi-step workflows. Looking ahead, Gartner predicts that 40% of agentic AI projects will fail by 2027, driven largely by rising integration costs and architectural brittleness. These are not edge cases; they are the median outcome.
What unifies these failures is their origin in system design, not model hallucination. Agents routinely make non-replayable decisions, fail to exploit available external tools, and collapse when confronted with data that diverges from their sanitized training environments. When an agent combines actions across time without robust guardrails, small errors do not remain small—they cascade into operational failures. As one production analysis noted, the system is often “structurally unsafe” long before it ever reaches a user.
What Production-Grade Agents Actually Require
Closing this gap requires a fundamental shift in how teams build and deploy agentic systems:
For sectors like customer communication, where multi-turn conversations span 22 regional languages and unpredictable user intent, the production barrier is even higher. Platforms like CallMissed are already enabling businesses to deploy AI voice agents and WhatsApp chatbots that handle 24/7 customer interactions across this linguistic complexity, paired with access to 300+ LLMs and native speech-to-text infrastructure that supports 22 Indian languages. These systems illustrate that the path to production readiness is not generated by more demo hype—it is built through specialized infrastructure, rigorous multilingual testing, and bounded autonomy.
The Final Verdict
Autonomous AI is not inherently doomed to fail. But it will continue to fail in the real world until teams stop treating structural fragility as a temporary limitation and start treating it as the primary engineering problem to solve. The next generation of agentic deployments will not be defined by what their models can generate in a polished prototype, but by what their systems can reliably withstand when the APIs break, the context drifts, and the real-world queries arrive in languages the demo never tested. In an environment where nine in ten agents harbor exploitable vulnerabilities, survival belongs to the teams that build for breakage first—and intelligence second.
Conclusion
The path from autonomous AI agent prototype to production-ready system remains one of the most challenging frontiers in enterprise AI. As research from Elloe AI Research Lab and Stanford reveals, the vulnerabilities are not merely technical glitches but systemic weaknesses baked into how agents sequence actions across time. With Gartner predicting that 40% of agentic AI projects will fail by 2027—driven by spiraling costs and integration complexity—and industry data suggesting that 88% of deployments struggle with compounding errors, brittle API connectors, and context drift, the message is clear: successful agent deployment demands architectural rigor, not just impressive model performance.
Before greenlighting your next deployment, keep these hard-won lessons front of mind:
Looking ahead, the teams that will win are those treating agents as critical infrastructure—observable, governable, and cost-controlled—rather than as magic black boxes. Watch for the emergence of standardized agent orchestration layers, real-time cost dashboards, and security frameworks purpose-built for autonomous decision chains.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. As you evaluate where autonomous agents fit into your 2025 roadmap, ask yourself: Are you building a demo that impresses in a boardroom, or an architecture that survives the unrelenting chaos of real-world operations? The honest answer will determine whether you join the thin ranks of teams that scale—or the majority that learn these lessons the hard way.
Related Posts

Why Autonomous AI Agents Fail in Real-World Deployments: 7 Critical Failure Modes

AI Agents Security for Developers: Don't Let Your Agents Become a Liability

5NF and Database Design: A Complete Guide to Fifth Normal Form and Project-Join Dependencies