RAG Best Practices in 2026: Chunking, Reranking, Hybrid Search

RAG (retrieval-augmented generation) graduated from a 2023 buzzword to a 2026 production pattern, and along the way the industry agreed on what actually matters. Most quality wins come from four levers: chunking strategy, hybrid retrieval, rerankers, and the long-context vs RAG tradeoff. Get those four right and you are ahead of 80% of production deployments.
Chunking: where most quality is won or lost
The naive "split into 1000-character chunks every 100 characters" approach is a fast start and a slow ceiling. In 2026 the patterns that ship:
## headings; for code, split per function or class via AST; for legal text, split per clause with full-paragraph context.A common failure: chunks that are too small ("one sentence each") perform worse on multi-step reasoning. 512–1024 tokens with structure-aware boundaries is the safe default for prose.
Hybrid retrieval: dense + lexical, always
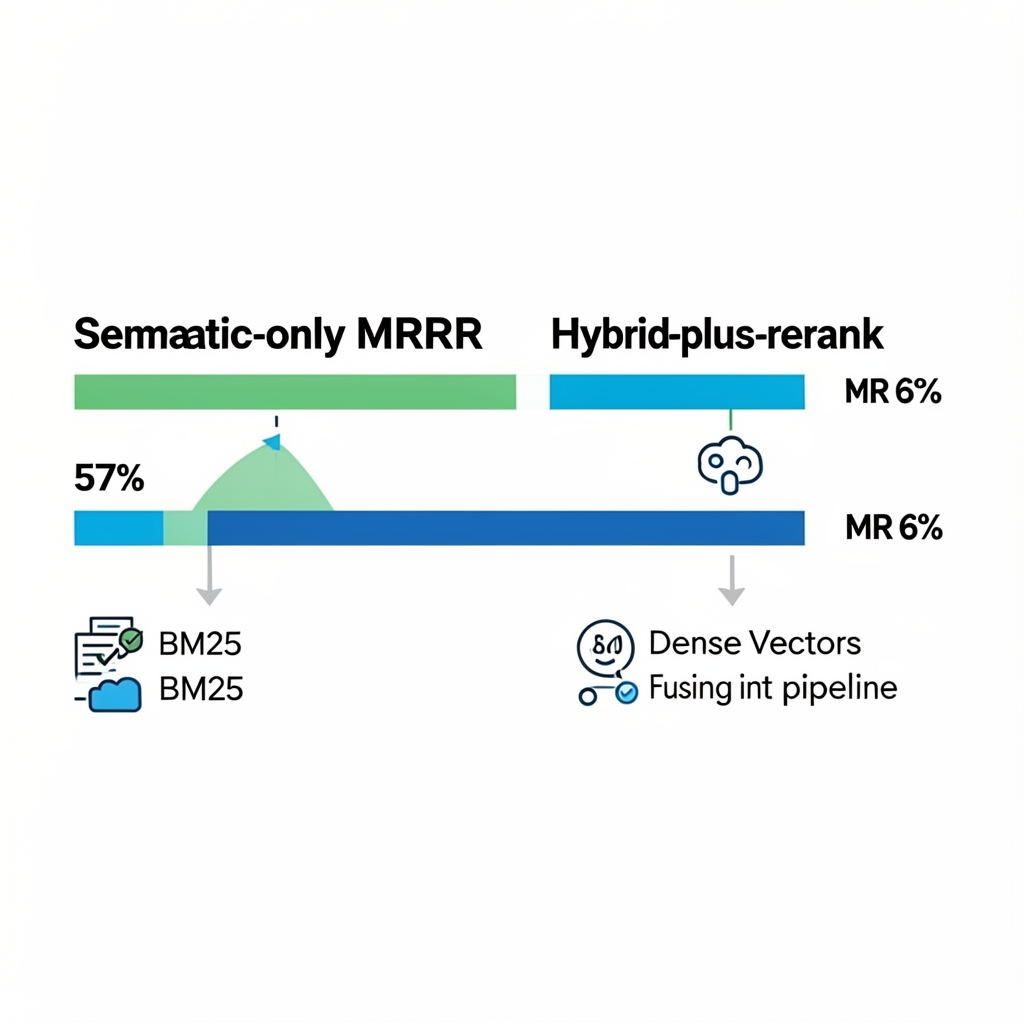
Dense embeddings are good at semantics but bad at exact matches — names, SKUs, dates, error codes. BM25 (a lexical scoring function) is the inverse. Combining them — hybrid retrieval — is consistently better than either alone.
In benchmarks reported by Superlinked and others, hybrid + rerank reached MRR around 66% on tested datasets versus around 57% for semantic-only — roughly a 9-point gain. (VectorHub) [Unverified — single benchmark]
Two ways to fuse:
If your stack supports it natively (Weaviate, Qdrant with sparse vectors, Elasticsearch, OpenSearch), use the built-in operator. If not, retrieve top-k from each path independently and fuse outside the database.
Rerankers: the highest-ROI step
Initial retrieval is "fast and approximate." A reranker takes a small candidate set (say, top 20–50) and re-scores each with a heavier model that looks at query + chunk together. Cross-encoders are slower per pair but materially more accurate.
In 2026 the practical choices:
Rule of thumb: retrieve 20, rerank to 5, send 3–5 to the LLM. Reranking 100+ candidates rarely pays off; the head of the distribution carries the signal.
Long context vs RAG: not "one wins"
Frontier models in 2026 have million-token context windows. The reflex "we don't need RAG anymore" is wrong for three reasons:
The 2026 consensus pattern: RAG retrieves, long context refines. Pull 5–20 reranked chunks, hand them to the model in a 16–64K-token prompt with system instructions and examples. Use the full context window when synthesis genuinely demands it (long reports, codebases) — not as a substitute for retrieval.
Evaluation: the part most teams skip
You cannot improve what you do not measure. The minimum viable eval:
Run this on every config change. The number of teams that "improved" their pipeline and quietly regressed retrieval is non-trivial.
A 2026-default RAG pipeline
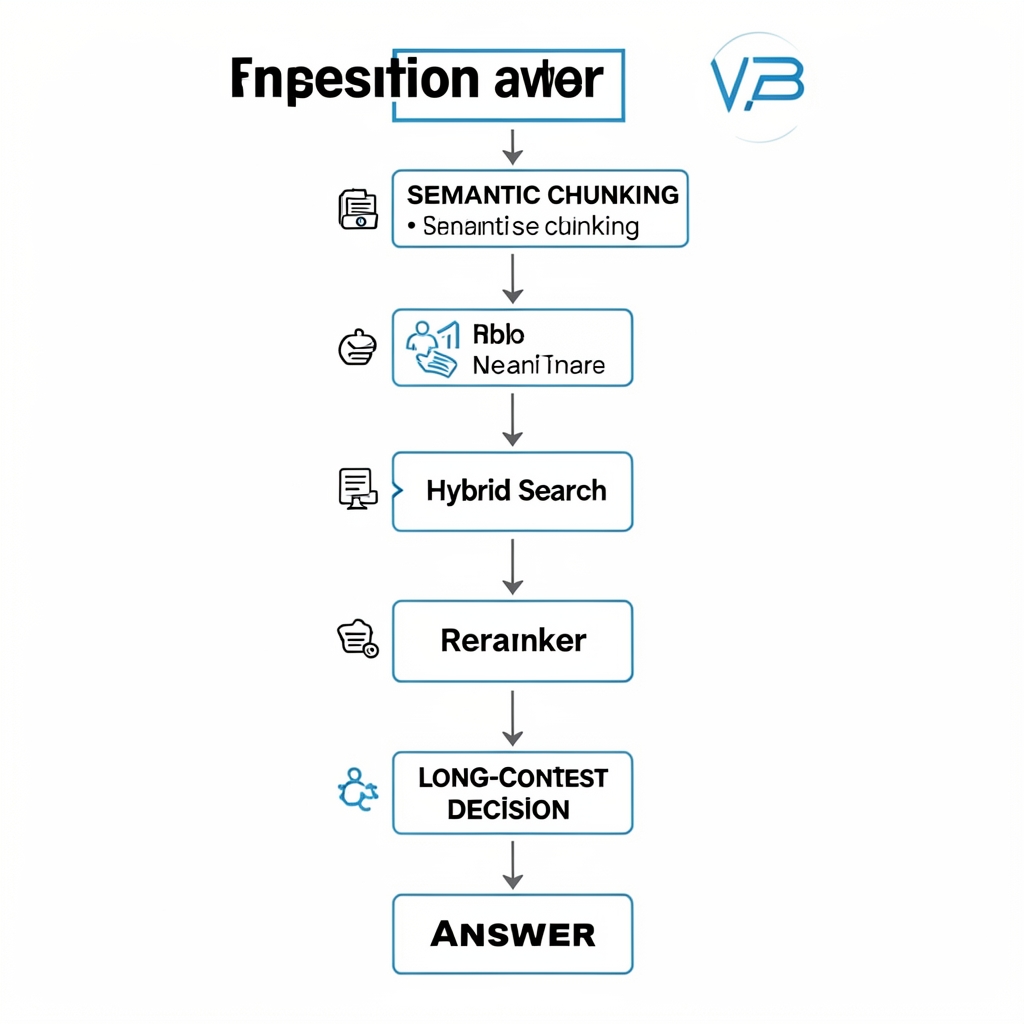
query
→ query rewrite (optional, helps multi-turn)
→ hybrid retrieval (dense top-50 + BM25 top-50, RRF fused)
→ reranker (Cohere or Voyage) → top 5–8
→ context builder (with metadata + citations)
→ LLM with structured output for citationsThis pipeline is boring on purpose. Each step earns its keep, and each step is independently swappable when something better ships.
Bottom line
The fastest way to better RAG in 2026 is not "use Claude 4.5 instead of GPT-4." It is chunk better, retrieve hybrid, rerank aggressively, and measure. Frontier models help, but they amplify the quality of what you feed them. Garbage in still produces confidently-worded garbage out.


