N-Day-Bench: Can LLMs Find Real Vulnerabilities in Real Codebases?

N-Day-Bench: Can LLMs Find Real Vulnerabilities in Real Codebases?
_Intro generation failed: Blog LLM (@cf/moonshotai/kimi-k2.6) returned empty/null content: {'id': 'id-1778937487048', 'object': 'chat.completion', 'created': 1778937487, 'model': '@cf/moonshotai/kimi-k2.6', 'choices': [{'finish_reason': 'length', 'index': 0, 'logprobs': None, 'matched_stop': None, 'message': {'content': None, 'reasoning_content': 'The user wants an engaging introduction (_
Introduction
The cybersecurity community has a credibility problem when it comes to evaluating AI. For years, static vulnerability discovery benchmarks have dominated the conversation, but they suffer from a fatal flaw: they become outdated almost as quickly as they are published. Cases leak into training data, and before long, benchmark scores stop measuring reasoning and start measuring memorization. Enter N-Day-Bench, a new evaluation framework that is currently trending on HackerNews (67 points, 18 comments in under 12 hours) and promising to reset the standard for how we test large language models on real-world security tasks.
Beyond Static Benchmarks
N-Day-Bench addresses a critical gap in AI security evaluation. Rather than relying on stale datasets, it tests whether frontier LLMs can find known security vulnerabilities in actual repository code. The framework's methodology is deliberately hands-on:
The urgency of this approach is underscored by recent research from UC Berkeley, which demonstrated that eight major AI benchmarks—including SWE-bench and WebArena—can be gamed or suffer from data contamination. When models are evaluated on fixed datasets, performance metrics become increasingly unreliable over time.
A Moving Target by Design
What sets N-Day-Bench apart is its monthly refresh cycle. By continuously cycling in new vulnerabilities disclosed after each model's knowledge cut-off, the benchmark stays ahead of the contamination curve. This methodology directly challenges the "train and memorize" dynamic that has plagued other evaluations. Static benchmarks degrade precisely because known cases seep into training corpora, inflating scores without improving actual capability.
The framework arrives alongside other next-generation security benchmarks:
Together, these tools represent a decisive shift from theoretical testing to adversarial, real-world validation.
Implications for AI Security Infrastructure
As organizations rush to deploy AI for software security, the difference between memorized answers and genuine vulnerability discovery translates directly to risk exposure. N-Day-Bench's live-shell methodology mirrors how human security researchers actually work: given a codebase and a hint, explore, hypothesize, and exploit.
This demand for true reasoning capability reinforces why access to diverse, state-of-the-art models matters. Platforms like CallMissed, which provide LLM inference across 300+ models through a unified API gateway, enable security teams and researchers to rapidly benchmark different frontier agents against dynamic evaluations like N-Day-Bench without re-architecting their testing pipelines.
The question N-Day-Bench poses is deceptively simple: can your AI find a vulnerability it has never seen before in code written by someone else? As the benchmark gains traction, it may become the new baseline for separating genuinely capable security agents from cleverly memorizing pattern matchers.
Background & Context

The Problem with Static AI Security Benchmarks
Traditional vulnerability detection benchmarks have a critical flaw: static datasets rot. Once published, test cases inevitably leak into training corpora. Models begin optimizing for memorized answers rather than genuine reasoning. As noted by the N-Day-Bench team, scores on conventional benchmarks gradually shift from measuring capability to measuring data contamination.
This isn't theoretical. UC Berkeley researchers recently demonstrated that eight major AI benchmarks—including SWE-bench and WebArena—suffer from structural vulnerabilities that allow models to exploit known patterns rather than solve novel problems. In security engineering specifically, this contamination is fatal. A model that memorizes CVE patches is useless against tomorrow's zero-day.
How N-Day-Bench Changes the Game
N-Day-Bench introduces a living benchmark architecture designed to stay ahead of model training data. Here's how it works:
This approach directly addresses the memorization problem. Because cases are updated monthly and drawn from live advisories, frontier LLMs cannot have seen the specific pre-patch code during training.
The Broader Benchmarking Landscape
N-Day-Bench arrives amid a wave of next-generation security benchmarks. In 2025, H. Lee et al. introduced SEC-bench, the first fully automated framework for evaluating LLM agents on authentic security engineering tasks, which has already garnered 29 citations. Meanwhile, ZERODAYBENCH focuses specifically on evaluating LLM agents' ability to find and patch novel vulnerabilities in production codebases.
What distinguishes N-Day-Bench is its focus on N-Day vulnerabilities—known flaws that are nonetheless new to the model. This creates a pragmatic middle ground between synthetic CTF challenges and high-stakes zero-day hunting. Researchers can verify ground truth definitively (the patch exists) while still testing genuine discovery capability.
Why This Matters Now
The security industry faces an automation paradox. Static Application Security Testing (SAST) and Software Composition Analysis (SCA) tools generate thousands of alerts, yet developers struggle to prioritize them. LLM agents that can authentically reason about real codebases could transform this workflow—if we can trust their evaluations.
Platforms like CallMissed, which provide infrastructure for deploying and testing 300+ LLM models, illustrate why rigorous benchmarks matter. When organizations integrate AI into vulnerability management pipelines, they need confidence that model capabilities are measured against live code rather than contaminated training sets. Without benchmarks like N-Day-Bench, businesses risk deploying AI security agents that ace tests in the lab but fail when confronted with unfamiliar repositories.
The stakes here are concrete: misjudging an LLM's security reasoning capabilities doesn't just waste compute—it leaves production systems exposed.
Key Developments (TABLE)

The vulnerability-evaluation landscape has fractured into two competing philosophies: static memorization tests and live, adversarial sandboxes. For years, benchmarks built on historical CVE-fix datasets dominated academic leaderboards, but researchers have grown skeptical of their real-world utility. As noted in the HackerNews discussion that propelled N-Day-Bench to 67 points in under 12 hours, static cases inevitably leak into training corpora, causing models to optimize for recall rather than reasoning. This skepticism has catalyzed a wave of next-generation benchmarks and audits designed to measure true capability.
| Initiative | Primary Target | Core Methodology | Notable Result / Status |
|---|---|---|---|
| N-Day-Bench | Known N-day vulnerabilities in real repos | Monthly refresh from GitHub Security Advisories; sandboxed bash shell on pre-patch commit | Keeps test set ahead of training data contamination |
| SEC-bench | Authentic security engineering tasks | Fully automated LLM agent benchmarking framework | 29 citations (H Lee, 2025); presented at NeurIPS 2025 |
| ZERODAYBENCH | Unseen zero-day vulnerabilities | Evaluates finding & patching novel bugs in production codebases | Focuses on true zero-day discovery rate |
| UC Berkeley Audit | Benchmark integrity & robustness | Exposed vulnerabilities in 8 major AI benchmarks including SWE-bench and WebArena | Demonstrated measurable benchmark-gaming risks |
| LLM Agent Patching Study | Novel vulnerability remediation | Tests frontier LLM agents on practical repository detection | Agents found and patched 22 novel critical vulnerabilities |
| Static CVE Benchmarks | Historical vulnerability recall | Fixed datasets with known CVE-to-patch mappings | Increasingly criticized for data leakage and memorization |
What Separates N-Day-Bench from the Pack
N-Day-Bench occupies a unique position among these initiatives thanks to its operational design:
By contrast, SEC-bench—while groundbreaking as the first fully automated framework for authentic security engineering tasks and already garnering 29 citations (H Lee, 2025)—does not mandate the same monthly obsolescence. Meanwhile, ZERODAYBENCH evaluates LLM agents against unseen zero-day vulnerabilities in production codebases but lacks N-Day-Bench’s systematic refresh rhythm tied to live GitHub Security Advisories.
The Benchmark Integrity Crisis
The UC Berkeley audit adds another layer of urgency. By exposing structural weaknesses across eight major AI benchmarks—including SWE-bench and WebArena—the Berkeley team demonstrated that benchmark gaming is not a theoretical risk but a measurable phenomenon. In parallel, emerging research documented on ResearchGate shows that frontier LLM agents have already demonstrated the ability to find and patch 22 novel critical vulnerabilities in open-source repositories, proving that underlying agentic capabilities are real even if current evaluation regimes poorly measure them.
Infrastructure Implications
These developments collectively redefine what “production-ready” means for security-oriented LLMs. Static accuracy percentages are giving way to monthly survival rates. From an infrastructure perspective, this explosion of benchmark diversity creates operational friction for teams trying to evaluate models at scale. Solutions like CallMissed's multi-model API gateway, which lets developers switch between 300+ LLMs without code changes, are becoming critical for security research labs that need to test identical agentic workflows across N-Day-Bench, SEC-bench, and ZERODAYBENCH without maintaining separate integrations for each frontier provider. When a benchmark’s utility is measured in weeks rather than years, evaluation velocity becomes as important as model accuracy.
In-Depth Analysis
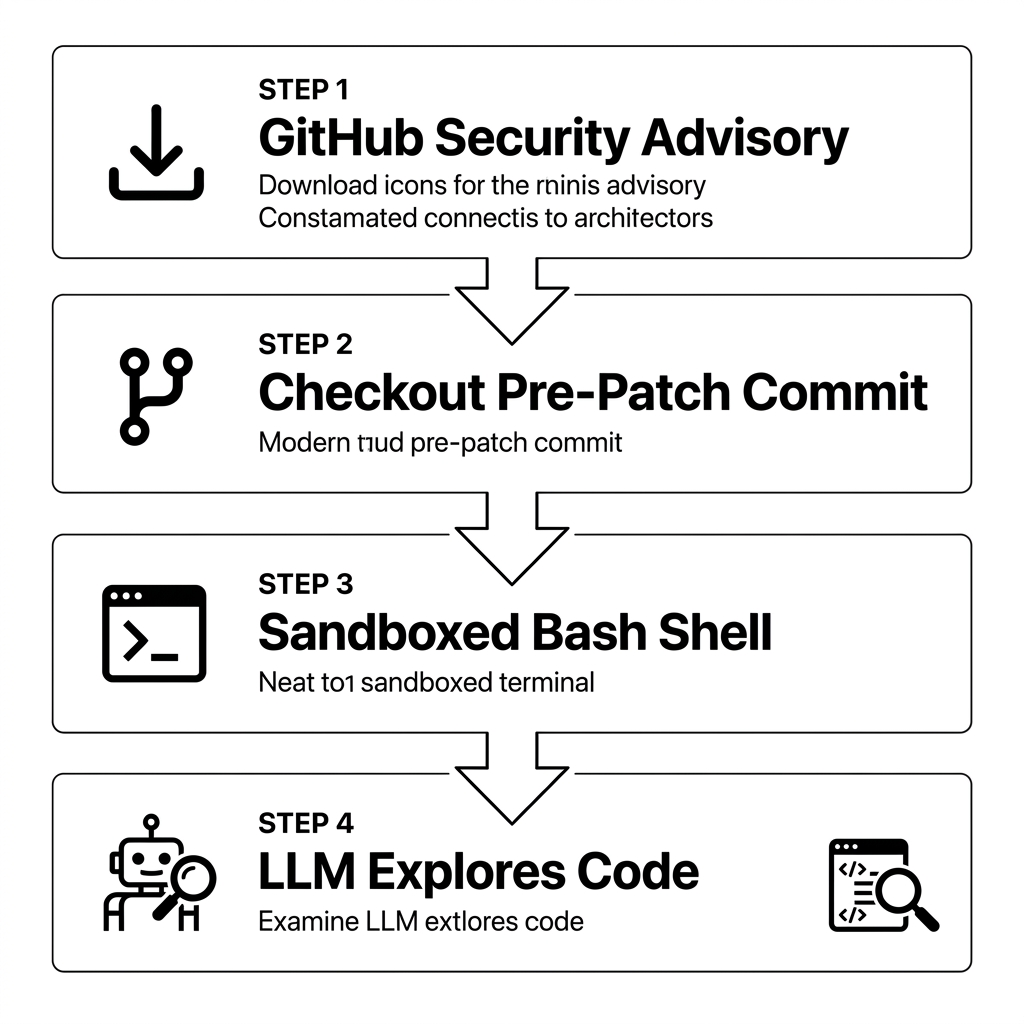
The Architecture of Realistic Evaluation
N-Day-Bench departs from static datasets by constructing a living pipeline that pulls fresh vulnerability cases each month directly from GitHub Security Advisories. For every selected CVE, the framework checks out the target repository at the last commit before the patch, presenting models with an unmodified, vulnerable codebase in its native environment. This methodological choice is critical: models must analyze real developer patterns, messy dependencies, and incomplete documentation rather than sanitized code snippets designed for classroom analysis.
The evaluation environment itself is equally consequential. Instead of receiving pre-isolated functions or multiple-choice prompts, models are granted a sandboxed bash shell and agentic freedom to explore the repository. This design mirrors how human security auditors actually work—grepping for sinks, tracing data flow across files, examining commit histories, and reasoning about build configurations. The shift from passive classification to active discovery represents a meaningful evolution in how the industry measures capability over memorization.
Escaping the Contamination Trap
Static vulnerability benchmarks face an existential problem: training data contamination. As datasets age, their cases inevitably leak into pre-training corpora and fine-tuning sets, causing scores to gradually measure recall rather than reasoning. UC Berkeley researchers demonstrated this vulnerability explicitly, showing that eight major AI benchmarks—including SWE-bench and WebArena—can be inflated or gamed through prior data exposure.
N-Day-Bench counters this through its monthly refresh cycle, continuously moving the goalpost ahead of model training cut-offs. By focusing on N-day vulnerabilities disclosed after a model’s knowledge deadline, the benchmark forces genuine reasoning. The framework explicitly tests whether frontier LLMs can discover flaws they were never trained to recognize, closing the gap between leaderboard performance and real-world utility.
The Broader Benchmark Ecosystem
N-Day-Bench operates within a rapidly maturing landscape of security-focused evaluation frameworks:
Together, these initiatives reveal a clear consensus: the community is migrating from function-level classification to dynamic, repository-level evaluation. For security teams operationalizing these capabilities, testing across multiple frontier models is no longer optional. Platforms such as CallMissed, which offer inference access to 300+ LLMs through a unified API gateway, allow researchers to run head-to-head evaluations against living benchmarks like N-Day-Bench without retooling their infrastructure for every model release. As the distance between benchmark scores and real exploits continues to narrow, that kind of seamless, multi-model access becomes essential for separating genuine capability from contaminated hype.
Impact & Implications

Redefining Benchmark Integrity in AI Security
The most immediate impact of N-Day-Bench is its direct challenge to benchmark contamination—the Achilles' heel of static vulnerability discovery datasets. Traditional benchmarks decay almost immediately: cases leak into training corpora, and model scores quickly reflect memorization rather than reasoning. N-Day-Bench counters this by pulling fresh cases monthly from GitHub security advisories and evaluating models against the exact pre-patch commit. This cadence keeps the test set ahead of model knowledge cut-offs, forcing frontier LLMs to demonstrate genuine exploit comprehension instead of pattern matching.
This approach arrives at a critical moment. Researchers from the University of California, Berkeley recently demonstrated that eight major AI benchmarks—including SWE-bench and WebArena—can be systematically exploited, casting doubt on headline performance claims across the industry. By grounding evaluations in real, recently disclosed vulnerabilities with a living dataset, N-Day-Bench restores a level of empirical rigor that static suites can no longer guarantee.
Closing the Gap Between N-Day and Zero-Day Discovery
Beyond benchmarking ethics, the framework signals a broader inflection point: LLM agents are transitioning from academic curiosities to active security researchers. Complementary work cited in the context highlights this trajectory. SEC-bench (H Lee, 2025, cited by 29) introduced the first fully automated framework for authentic security engineering tasks, while ZERODAYBENCH explicitly evaluates agents on unseen, novel vulnerabilities in production codebases rather than known issues. The distinction matters enormously. Finding an N-day in a pre-patch repository mirrors the real-world conditions of zero-day discovery—unknown bugs, messy context, and no labeled answer key.
The empirical results support this optimism. In related studies, LLM-based agents have already demonstrated the ability to find and patch 22 novel critical vulnerabilities in open-source codebases. N-Day-Bench provides the reproducible proving ground needed to refine these capabilities at scale, separating models that can reason about code execution from those that merely hallucinate CVE descriptions.
Operationalizing AI-Augmented Security
For enterprise security teams, the implications extend far beyond research leaderboards. As N-Day-Bench validates which frontier models excel at real-world code exploration, organizations gain an objective lens for selecting AI copilots for AppSec and DevSecOps workflows. Rather than replacing static application security testing (SAST) or software composition analysis (SCA) tools, these agents are poised to prioritize and contextualize their output—directly addressing the alert fatigue generated by hundreds of noisy scanner findings.
Deploying vulnerability-hunting agents in production, however, introduces several infrastructure requirements:
This is where communication infrastructure intersects with model performance. Platforms such as CallMissed provide API gateways to 300+ LLMs, enabling security orchestration layers to dynamically route inference workloads as benchmark leaderboards evolve. When an agent flags a critical issue, integrating those findings into voice or messaging workflows ensures that AI-discovered vulnerabilities reach human responders within minutes rather than days.
The bottom line is clear: benchmarks like N-Day-Bench do not merely rank models. They accelerate the entire security industry's transition toward autonomous, evidence-based vulnerability management.
Expert Opinions
The HackerNews Reception and Immediate Community Response
N-Day-Bench gained significant traction upon release, hitting the top of HackerNews with 67 points and 18 comments within just 11.6 hours. This rapid engagement signals a hunger within the developer and security research communities for benchmarks that reflect genuine capability rather than memorized training data. The discussion centered on a critical pain point: static vulnerability discovery benchmarks degrade quickly because cases leak into training corpora, causing scores to measure memorization rather than reasoning. By pulling fresh cases monthly from GitHub Security Advisories—specifically evaluating whether frontier LLMs can identify N-Day vulnerabilities disclosed after their knowledge cut-off—and checking out repositories at the exact pre-patch commit, N-Day-Bench attempts to stay ahead of this contamination curve.
Academic Scrutiny of Benchmark Integrity
The methodology arrives amid growing skepticism about traditional AI evaluation frameworks. Researchers from the University of California, Berkeley demonstrated that eight major benchmarks—including prominent coding and web interaction tests like SWE-bench and WebArena—suffer from structural vulnerabilities that compromise their validity. This broader crisis of confidence makes N-Day-Bench's monthly refresh mechanism particularly relevant. Experts note that the sandboxed bash shell access, which gives models freedom to explore real repository code, more accurately mirrors how security engineers actually audit codebases compared to static multiple-choice or single-file analysis tasks.
Parallels and Distinctions with Related Frameworks
The expert discourse increasingly distinguishes between different tiers of security evaluation:
Experts argue that these benchmarks form a capability maturity spectrum. Work published on ResearchGate indicates that frontier LLM agents can find and patch 22 novel critical vulnerabilities in open-source repositories, suggesting the gap between N-Day rediscovery and true zero-day research is narrowing—but remains substantial. The consensus view holds that N-Day-Bench fills a necessary niche as a "live" proving ground: because cases rotate monthly and derive from real advisories, it offers a harder-to-game alternative to static datasets, even if it does not yet capture the full creative demands of original vulnerability research.
The Path Forward
Security researchers emphasize that the ultimate test for LLM agents is not recall of known bugs, but the ability to reason about unfamiliar architectures under constraints. N-Day-Bench's decision to provide autonomous exploration capabilities via a sandboxed environment aligns with expert calls for agent-centric evaluation. However, opinions diverge on whether monthly refreshes alone can outrun the accelerating pace of model training data ingestion. As the field evolves, expert opinion increasingly favors continuously evolving evaluation pipelines that mirror the CI/CD workflows of modern software engineering, ensuring that tomorrow's security agents are tested against tomorrow's code—not yesterday's leaked benchmarks.
What This Means For You (TABLE)
The Hacker News community’s response—67 points and 18 comments in just 11.6 hours—confirms that security and AI engineering teams are exhausted by benchmark theater. N-Day-Bench’s philosophy is simple but disruptive: pull fresh vulnerability cases monthly from GitHub Security Advisories, checkout the repository at the last commit before the patch, and give models a sandboxed bash shell to explore real code. For practitioners shipping production systems, this shift demands a recalibration of how we procure, build, and trust AI security tools.
| Your Role | The N-Day-Bench Shift | Old Mindset | New Action Item | Impact Timeline |
|---|---|---|---|---|
| Security Engineer | Real-repo evaluation replaces static CTF questions | Trusting leaderboard accuracy on stale datasets | Augment SAST pipelines with sandboxed LLM agents authorized to explore code dynamically | Immediate |
| AI/ML Researcher | Contamination resistance is now table stakes | Publishing top-line scores from fixed benchmarks | Design rolling benchmarks with disclosure cut-off dates and adversarial decontamination checks | Next quarter |
| DevSecOps Lead | Agentic patching has proven real-world viability | Treating AI as a chat-only copilot | Deploy autonomous agents in staging CI/CD to suggest patches for newly disclosed N-days | 6–12 months |
| Engineering Manager | Prominent benchmarks are gameable | Buying tools based on marketing benchmark claims | Demand proof against live repositories; UC Berkeley showed 8 major benchmarks can be exploited | Immediate |
| Startup Founder | Continuous security triage is becoming core infrastructure | Manual review of upstream security advisories | Automate dependency monitoring with agents that reason over actual commit histories | Ongoing |
The End of Static Benchmark Reliability
Static vulnerability discovery benchmarks degrade the moment they are published. As the N-Day-Bench project notes, cases leak into training data, and scores quickly start measuring memorization rather than reasoning. This mirrors findings from UC Berkeley researchers who demonstrated that eight major AI benchmarks, including SWE-bench and WebArena, can be gamed. For buyers, this means a “90% accuracy” claim on a fixed corpus is now a red flag unless the vendor can demonstrate monthly, live-repo performance. The only metric that matters is how a model performs on code it has never seen—evaluated in an environment where it can actually run grep, read files, and trace execution.
From Academic Proofs to Production Agents
The capability gap is closing faster than procurement cycles. Recent research shows that LLM agents can find and patch 22 novel critical vulnerabilities in open-source production codebases, while Lee et al.’s SEC-bench (2025, cited by 29) offers the first fully automated framework for authentic security engineering tasks. ZERODAYBENCH extends this even further by testing unseen zero-day scenarios. These results imply that your next security hire might be an agent, not a human—but only if the underlying infrastructure can support rapid model iteration.
For teams moving from evaluation to deployment, infrastructure agility is critical. Platforms like CallMissed provide multi-model API gateways that let security teams route vulnerability-discovery tasks across 300+ LLMs, enabling side-by-side testing of which model handles real repository exploration best. In an era where benchmark integrity determines security posture, the ability to swap models without code changes is not a convenience—it is a risk mitigation strategy.
Bottom-line priorities for practitioners:
Frequently Asked Questions
What is N-Day-Bench and how does it evaluate LLMs on real vulnerabilities?
How does N-Day-Bench prevent benchmark contamination and training data memorization?
What is the difference between N-Day-Bench and static security benchmarks like SEC-bench?
Can LLM agents actually find and patch exploitable vulnerabilities in real open-source codebases?
How does N-Day-Bench compare to ZERODAYBENCH and other AI security benchmarks?
What infrastructure does N-Day-Bench use to test AI agents on real repository code?
Conclusion
Why N-Day-Bench Changes the Security Benchmarking Game
N-Day-Bench represents a necessary evolution in how we evaluate frontier AI systems. Unlike static benchmarks that quickly become obsolete as cases leak into training data, its monthly refresh of real GitHub security advisories ensures models are tested against vulnerabilities disclosed after their knowledge cut-off. By checking out repositories at the last commit before the patch and providing a sandboxed bash shell, the benchmark forces LLMs to demonstrate genuine vulnerability discovery rather than rely on memorized solutions.
The context is stark: UC Berkeley researchers have exposed that eight major AI benchmarks, including SWE-bench and WebArena, can suffer from contamination and methodological flaws. When scores measure memorization rather than reasoning, the entire field optimizes for the wrong target. N-Day-Bench's methodology directly addresses this by evaluating whether models can find known but freshly disclosed vulnerabilities in real codebases—testing the exact skill security teams need: understanding code they have never seen before, under conditions that mirror actual incident response.
From N-Days to Zero-Days: The Road Ahead
The security implications extend far beyond academic scoring. While N-Day-Bench focuses on recently published vulnerabilities, parallel efforts are pushing into more challenging territory:
This suggests the gap between assisted analysis and autonomous discovery is narrowing faster than anticipated. The benchmark's reception—trending on HackerNews with 67 points and 18 comments in just 11.6 hours—signals that the security community is hungry for rigorous, contamination-resistant evaluation.
Implications for AI Infrastructure and Deployment
For teams building production AI systems, the lesson is clear: model selection must prioritize dynamic capability over static leaderboard performance. Platforms like CallMissed, with multi-model API gateways supporting 300+ LLMs, enable businesses to route security-sensitive tasks to models validated on live benchmarks rather than outdated training set proxies. The ability to switch between frontier models without code changes becomes critical when benchmarks reveal which models actually reason through unfamiliar code versus those that merely memorize patches.
The trajectory points toward a future where AI security tools undergo the same adversarial scrutiny as the code they analyze. The monthly cadence of N-Day-Bench, combined with emerging research on agentic vulnerability discovery, suggests we are moving from proof-of-concept demonstrations to systems that can meaningfully augment core aspects of security engineering.
The question is no longer whether LLMs can find real vulnerabilities in real codebases. N-Day-Bench and its successors prove they can, under rigorous, contamination-resistant conditions. The question now is how quickly organizations can integrate that capability into secure, verifiable workflows—routing complex security analysis to the right models, auditing their outputs, and closing the gap between laboratory benchmarks and production-ready defense—before adversaries exploit the same techniques at scale.


