DeepSeek V4: Everything to Know About the New Open-Source AI Model

DeepSeek V4: Everything to Know About the New Open-Source AI Model
What if the world's most capable open-source AI model cost nearly three-quarters less to run than its closed-source rivals—and could remember every detail you've shared across a million-word conversation? That isn't a speculative pitch anymore; it's the reality DeepSeek V4 delivered when it stunned the industry in early 2026. The Chinese startup that previously sent shockwaves through Silicon Valley with world-leading processing power at a fraction of Big Tech's costs has returned with its most ambitious release yet, and the benchmark numbers are already forcing a reckoning across the global AI landscape.
DeepSeek V4 delivers performance that matches or beats several proprietary models on agentic tasks at roughly 27% of the compute cost, according to independent evaluations. Its staggering 1 million token context window, paired with 10x KV cache savings, enables the model to ingest entire codebases, legal libraries, or research archives in a single pass without the crippling latency that usually bottlenecks long-context inference. In world knowledge benchmarks, DeepSeek V4-Pro doesn't merely lead the open-source category—it significantly outperforms every competitor and sits only slightly behind the most expensive closed models, despite being freely available for developers to download, fine-tune, and deploy at scale.
This release matters because the AI industry has reached an inflection point where cost efficiency, context length, and open accessibility are becoming as critical as raw parameter count. DeepSeek V4 is reportedly built on a 1 trillion parameter architecture featuring novel innovations like mHC architecture and Engram Memory, making it specifically optimized for complex coding workflows, multi-step reasoning, and extended document analysis with millisecond response times. By pairing frontier-level capability with ultra-low pricing, DeepSeek is dismantling the assumption that cutting-edge AI requires billion-dollar infrastructure and proprietary API lock-in. For startups and enterprises alike, high-performance agentic automation and advanced code generation are suddenly available without enterprise licensing gates.
In this article, we'll unpack everything you need to know about DeepSeek V4—from its technical architecture and real-world benchmark performance to its pricing implications and broader impact on the open-source ecosystem. We'll also explore how this shift affects builders today, including why infrastructure platforms like CallMissed are already integrating next-generation LLMs into production-ready voice agents and multilingual chat infrastructure, allowing teams to leverage models like DeepSeek V4 without managing the underlying complexity.
Introduction
Just over a year after DeepSeek sent shockwaves through the artificial intelligence industry by delivering world-leading processing power at a fraction of Silicon Valley's costs, the Chinese startup has returned with its most ambitious release yet. DeepSeek V4 is no incremental update. With a confirmed release in early 2026 and specifications that read like a wish list for efficiency-obsessed engineers, V4 is already reshaping conversations around open-source AI, compute economics, and the global balance of model performance. Whether you are evaluating large language models for enterprise deployment or tracking the accelerating AI race between Chinese and Western labs, understanding V4's architecture and positioning is essential.
What DeepSeek V4 Brings to the Table
DeepSeek V4 arrives as a 1 trillion parameter flagship built on a novel mHC architecture and Engram Memory system, designed specifically to push performance boundaries without ballooning inference costs. The headline technical achievement is unmistakable: a 1 million token context window paired with 10x KV Cache savings, a combination that directly addresses the memory bottlenecks that have historically crippled long-document analysis, codebase ingestion, and extended agentic workflows.
Early benchmark reporting from EuroNews underscores the model's competitiveness: DeepSeek V4-Pro "significantly leads other open-source models" in world knowledge benchmarks and is only narrowly surpassed by the absolute top-tier proprietary systems. Meanwhile, independent analysis from MindStudio reveals that V4 delivers performance matching or beating several proprietary models on agentic tasks—while requiring roughly 27% of the compute cost. In an industry where API pricing often determines adoption velocity, that cost-performance ratio is not merely competitive; it is structural.
The Architecture Driving Efficiency
Beneath the benchmark headlines, V4's engineering choices tell a deeper story. The model introduces several architectural innovations designed to break the traditional trade-off between context length and inference cost:
These innovations allow the model to maintain coherence across its full context window without linearly scaling GPU memory demands—a problem that has made competing long-context models prohibitively expensive for many startups.
Why the Market Is Taking Notice
V4's efficiency breakthroughs land at a geopolitically charged moment. As GPU export controls continue to tighten, DeepSeek's ability to achieve ultra-low pricing and millisecond response times through software-level architecture innovations suggests that clever model design can partially offset hardware scarcity. The model is already being described as 2026's most powerful coding AI system, with particular strength in autonomous task execution—the "agentic" behaviors that enterprises are scrambling to productionize.
For developers and platform operators, the implications are immediate. The gap between open-source and proprietary inference is closing faster than incumbent pricing models anticipated. Production AI communication platforms—such as CallMissed, which runs multi-model voice agents, WhatsApp chatbots, and LLM inference APIs supporting over 300 models—stand to benefit directly from this efficiency revolution. As architectures like V4's mHC and Engram Memory mature, businesses deploying multilingual AI workflows will be able to route complex, long-context interactions through top-tier open-source models without absorbing the historic premium attached to closed-source performance. DeepSeek V4 does not just raise the bar for open-source AI; it redefines the economics of running it at scale.
Background & Context

The R1 Moment and What Came Before
DeepSeek’s ascent from a Hangzhou-based curiosity to a global AI powerhouse has redefined what the industry thought possible under hardware constraints. The startup first seized international attention when it shipped models with world-leading processing power at a fraction of the cost of American frontier labs, a breakthrough that triggered an “R1 moment” and sent shockwaves through tech markets. That release proved that cutting-edge AI capability was no longer the exclusive domain of well-capitalized U.S. giants, setting the stage for an even more ambitious successor.
From Rumor to Release: The V4 Buildup
The road to DeepSeek V4 was paved with months of speculation. By late 2025, technical leaks suggested a 1 trillion parameter flagship built on a novel mHC (multi-Head Compression) architecture and an Engram Memory system optimized for long-context retention. Initial timelines hinted at a February 2026 debut, but the formal unveiling arrived in April 2026, confirming the architectural rumors while revealing critical efficiency breakthroughs.
At launch, DeepSeek disclosed a suite of advances that quickly reset industry benchmarks:
This combination of scale and efficiency places V4 in elite company among both open and closed models.
Efficiency by Necessity: Export Controls and Global Competition
V4’s architecture is inseparable from its geopolitical context. U.S. export controls on advanced semiconductors have forced Chinese researchers to maximize algorithmic efficiency rather than relying on brute compute. The model’s sparse attention mechanisms, hybrid routing layers, and ultra-low pricing reflect what industry observers have termed “10× smarter AI under export controls”—a scenario where hardware limitations accelerate software innovation rather than suppress it. DeepSeek’s ability to ship a 1T-parameter model under these constraints has become a case study in doing more with less, pressuring global competitors to justify their own infrastructure spending.
The Open-Source Inflection Point
Beyond geopolitics, V4’s release sharpens the commercial tension between open-weights and closed API providers. By making a trillion-parameter model freely available that rivals—and sometimes exceeds—proprietary performance on coding and reasoning benchmarks, DeepSeek has compressed pricing expectations across the board. This shift is already reshaping the enterprise infrastructure layer. Platforms such as CallMissed are integrating these massive open-source weights into production-grade API gateways, enabling businesses to route traffic between DeepSeek V4 and proprietary LLMs without refactoring their client code. As the background to this release makes clear, V4 is not merely a model upgrade; it is a structural reset for how frontier AI capability is distributed, priced, and deployed globally.
Key Developments (TABLE)
DeepSeek V4 is not an incremental upgrade—it is a structural recalibration of what open-source AI can achieve. Released in February 2026, the model combines a 1-trillion-parameter scale with a 1-million-token context window, wrapped in an architecture explicitly optimized for long-context efficiency and coding dominance [5][6]. Below is a detailed breakdown of the technical developments that define V4’s competitive posture.
| Key Development | Technical Specification | Competitive Significance | Evidence |
|---|---|---|---|
| Long-Context Prowess | 1 million token context window with 10× KV Cache compression | Analyzes entire codebases, legal contracts, or video transcripts in a single pass | DeepSeek reports millisecond response times even at full 1M context [2][8] |
| Memory Architecture | mHC architecture paired with Engram Memory | Faster retrieval and lower inference overhead than dense transformer stacks | Atlascloud cites this as a revolutionary leap for coding workflows [4] |
| Model Scale | 1 trillion parameters | Matches the raw capacity of the largest proprietary frontier models | DeepSeek V4 model guide lists 1T parameter scale [6] |
| Agentic Benchmarks | Matches or beats proprietary models on agentic tasks | Delivers automation-grade reliability without closed API lock-in | MindStudio analysis shows ~27% compute cost versus closed rivals [3] |
| Coding Leadership | Top-tier code generation and reasoning | Directly challenges GitHub Copilot, Cursor, and other coding assistants | Described as "2026's most powerful coding AI model" [4] |
| Knowledge & Reasoning | V4-Pro significantly leads open-source models; trails only top-tier closed models | Closes the reasoning gap with GPT-4o/Claude at open-source weights | EuroNews benchmark coverage confirms near-parity with frontier leaders [1] |
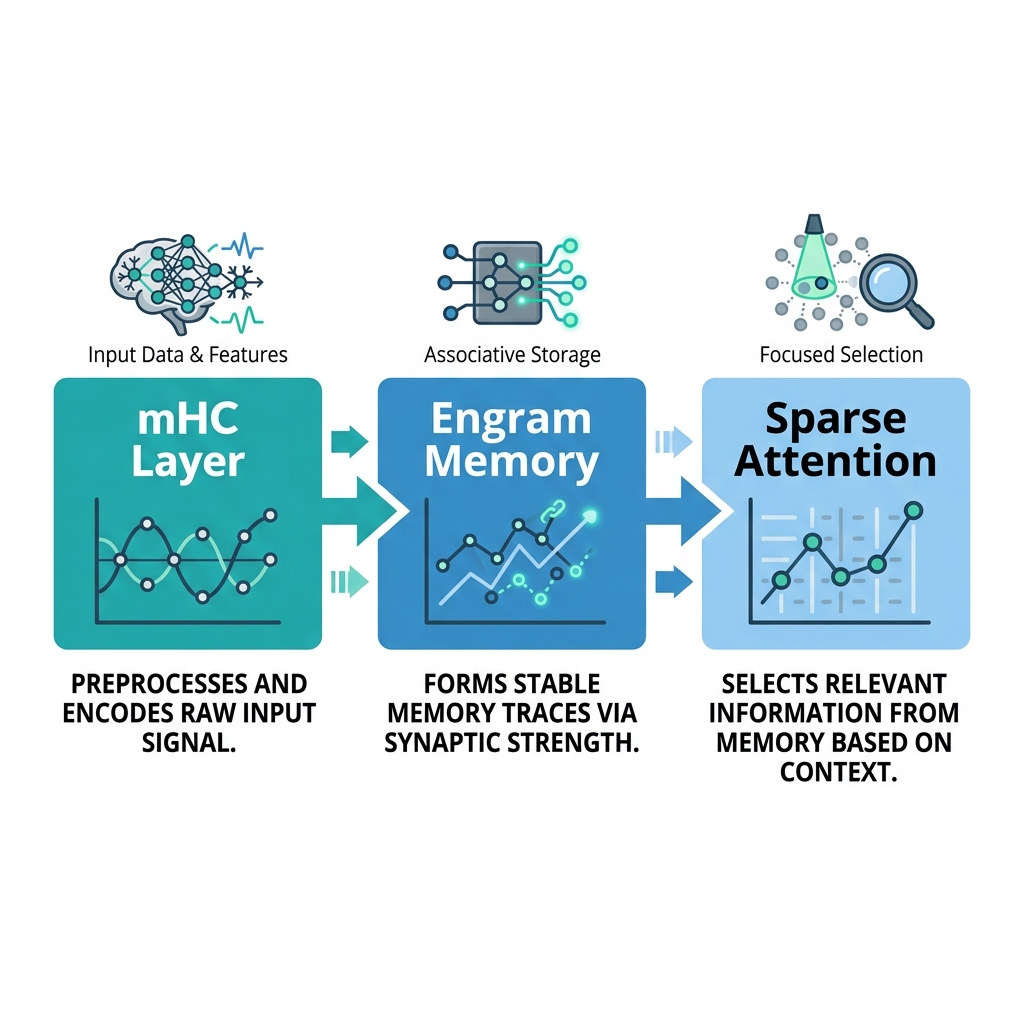
Architectural Revolution: mHC and Engram Memory
At the heart of these gains sits DeepSeek’s mHC (multi-head complementary) architecture and the newly introduced Engram Memory system. Unlike standard transformer stacks that redundantly recompute attention over massive contexts, the mHC design partitions computation across specialized sub-modules, while Engram Memory acts as a rapid-recall layer for frequently accessed patterns.
The structural choices yield tangible deployment benefits:
For production workloads, this means longer conversational threads and larger document batches without the typical throughput collapse.
Cost Efficiency and Open-Source Accessibility
DeepSeek has coupled raw capability with aggressive cost engineering. MindStudio analysis confirms V4 matches or beats proprietary models on agentic tasks at roughly 27% of the compute cost [3]. This pricing pressure manifests in several ways:
By releasing V4 as an open-weight model, DeepSeek undermines the traditional SaaS-GPT pricing moat that has dominated since 2023.
Implications for Production AI Infrastructure
For businesses building on next-generation LLMs, the technical blueprint of V4 offers a new template: million-token contexts, sparse attention savings, and radically open weights. As inference costs fall, communication infrastructure providers can pass those savings to end users. Indian startups like CallMissed exemplify this shift, offering production-ready voice agent infrastructure that leverages multi-model flexibility—allowing enterprises to switch between 300+ LLMs, including high-efficiency open models like DeepSeek V4, based on task complexity and localized language requirements. The result is a rapidly democratizing stack where frontier capability no longer requires frontier budgets.
In-Depth Analysis
Architecture and Efficiency Breakthroughs
DeepSeek V4’s technical foundation rests on a Mixture-of-Hyper-Connect (mHC) architecture integrated with Engram Memory, a combination purpose-built for sustained long-context coherence and rapid retrieval across vast token spans. Rather than simply scaling parameters, DeepSeek targeted inference efficiency. Key architectural specifications include:
These efficiency gains directly attack the memory bandwidth bottleneck that typically makes long-context inference prohibitively expensive. By reducing KV cache overhead by an order of magnitude, V4 enables enterprises to load entire codebases, legal libraries, or multi-hour transcripts into a single prompt without relying on fragmented retrieval-augmented generation (RAG) pipelines.
Benchmark Performance and Agentic Leadership
On standardized evaluations, DeepSeek V4-Pro has claimed the open-source frontier in world knowledge tasks. Release benchmarks show it “significantly leads other open source models and is only slightly outperformed by the top-tier proprietary systems.”
The model’s most disruptive results appear in agentic and coding workloads:
This cost-performance profile challenges the assumption that frontier autonomy requires frontier infrastructure budgets.
Market Positioning Under Export Controls
DeepSeek launched V4 within a geopolitical environment shaped by semiconductor export controls, demonstrating that hardware constraints are not absolute barriers to algorithmic efficiency. The release is paired with ultra-low pricing, reinforcing a market-warping dynamic: intelligence that rivals—or exceeds—Western proprietary APIs at a fraction of the operating cost. For global developers, the economic arbitrage is stark; a 1T-parameter model with million-token context and elite coding performance can be deployed locally or via regional cloud providers at costs historically associated with mid-tier offerings.
Infrastructure Implications for Enterprise Deployment
The confluence of 1M context, 10x cache efficiency, and open weights alters how enterprises should architect production AI stacks. Teams can consolidate document analysis, software engineering, and multi-turn agentic workflows onto a single model class, reducing orchestration complexity. Yet the rapid release of high-caliber open models also fragments the deployment landscape, forcing engineers to manage context limits, pricing tiers, and regional availability across dozens of providers.
This complexity increases the strategic value of model-agnostic infrastructure. Platforms like CallMissed, which provide multi-model API gateways spanning 300+ LLMs, allow engineering teams to route traffic to DeepSeek V4 for long-context coding tasks while seamlessly failing over to specialized models for voice or chat workflows—without rewriting application code. As open models continue closing the gap with proprietary frontiers, competitive advantage will belong to organizations that can orchestrate across them fluidly rather than those locked into a single vendor.
Impact & Implications

Redefining Cost-Efficiency in Production AI
DeepSeek V4’s most immediate industry impact is its aggressive cost-efficiency. According to MindStudio, the model delivers performance matching or beating several proprietary models on agentic tasks at roughly 27% of the compute cost required by closed-source alternatives. This is compounded by architectural innovations like 10x KV Cache savings and a 1 million token context window, which slash memory overhead during long-document inference. For AI teams running high-volume customer support, coding assistants, or research pipelines, this does not represent marginal savings—it fundamentally alters unit economics.
Key efficiency metrics driving this shift include:
Accelerating the Open-Source Advantage
In benchmark terms, DeepSeek V4-Pro “significantly leads other open source models and is only slightly outperformed by the top-tier” proprietary systems, Euroneus reported. The capability gap between open-weight and closed models is narrowing fastest in coding and agentic workflows, with AtlasCloud highlighting V4’s mHC architecture and Engram Memory as architectural differentiators purpose-built for software development. When an open-weight model with around 1 trillion parameters outperforms many US counterparts on coding benchmarks, enterprises face a genuine procurement dilemma: continue paying premium API rates for proprietary black boxes, or adopt transparent, fine-tunable weights that can be hosted privately.
Geopolitical and Infrastructure Implications
Released against a backdrop of tightening semiconductor export controls, DeepSeek V4 is being characterized as “10x Smarter AI Under Export Controls”—a clear signal that hardware restrictions have not stalled China’s frontier research. With promotional material citing millisecond response times and a claimed 1 trillion parameter scale achieved despite constrained GPU access, the release intensifies the geopolitical dimension of the AI race. It suggests that algorithmic efficiency—through sparse attention and hybrid routing architectures—can partially offset restricted access to the latest silicon. Western policymakers may be forced to confront whether export controls alone can preserve a competitive lead when algorithmic optimization delivers comparable scale at lower hardware budgets.
Enterprise Deployment and the API Landscape
The combination of 1M context windows, ultra-low pricing, and state-of-the-art coding performance positions V4 as a viable backbone for enterprise knowledge bases, legal document analysis, and autonomous software agents. For businesses evaluating integration, the practical implications are significant:
Yet most organizations will not self-host trillion-parameter models; they will consume them through managed inference layers. This creates natural demand for model-agnostic infrastructure. Platforms like CallMissed, which operate multi-model API gateways across 300+ LLMs, let engineering teams route production traffic to DeepSeek V4 without architectural lock-in, treating model selection as a configuration toggle rather than a codebase migration. For businesses operating in linguistically diverse markets, these efficiency gains also pair strategically with specialized communication stacks—such as CallMissed’s Speech-to-Text APIs supporting 22 Indian languages—to build end-to-end agentic pipelines that remain cost-effective at scale.
Ultimately, DeepSeek V4 does not merely add another entry to leaderboard rankings. By collapsing the cost-performance ratio and demonstrating that open architectures can challenge state-of-the-art proprietary systems under hardware constraints, it forces a strategic recalculation across pricing, deployment roadmaps, and national AI competitiveness.
Expert Opinions
Benchmarking Consensus: Closing the Gap on Proprietary Leaders
Industry analysts examining DeepSeek V4 agree that the model represents a structural inflection point for open-source competitiveness. Reporting from Euronews notes that DeepSeek V4-Pro "significantly leads other open source models" in world knowledge benchmarks and ranks only marginally below the most advanced proprietary systems. Independent technical reviews from MindStudio add further detail, finding that DeepSeek V4:
For researchers tracking the capability delta between commercial and open AI, the emerging consensus is that V4 has functionally erased the performance premium that historically justified proprietary pricing.
Architectural Innovation Under Constraint
Technical experts are particularly focused on how DeepSeek engineered around hardware bottlenecks to deliver these results. Reviewers at AtlasCloud highlight V4’s mHC architecture and Engram Memory as novel subsystems purpose-built to enhance long-context coherence and coding precision without proportionally inflating active parameter counts. The reported 10x KV Cache savings are especially significant for production deployments: by compressing the memory footprint required to maintain extended context states, the model can process lengthy legal contracts, video transcript archives, or large-scale code repositories on substantially leaner GPU configurations than dense alternatives. This efficiency breakthrough arrives alongside reports suggesting the model may scale to 1 trillion parameters, implying an aggressive use of sparse routing, hybrid attention, and conditional computation. Industry commentators have characterized this trajectory as achieving "10x smarter AI under export controls," observing that DeepSeek’s methodology effectively substitutes algorithmic and architectural refinement for unrestricted access to leading-edge semiconductor supply chains.
Strategic Implications for Enterprise Deployment
For CTOs and infrastructure architects, expert commentary signals a fundamental repricing of advanced reasoning capabilities. The 27% compute cost advantage is viewed not merely as a benchmark statistic but as a strategic shift that enables startups, regulated enterprises, and developers in cost-sensitive markets to self-host, fine-tune, or privately deploy frontier-class models without hyperscaler-level infrastructure budgets. V4’s reported specialization in coding tasks — repeatedly flagged across technical previews — also positions it as a direct challenger to domain-specific programming assistants currently locked behind premium subscriptions. As organizations reassess procurement strategies, observers note three immediate imperatives:
Platforms like CallMissed, which provide multi-model inference infrastructure for voice agents and automation pipelines, illustrate where the market is heading: giving businesses the ability to route high-efficiency open weights like DeepSeek V4 alongside proprietary endpoints based on latency, cost, and task requirements. Analysts agree that the barrier to enterprise-grade AI deployment is no longer model capability, but the speed at which teams can integrate these new efficiency benchmarks into production stacks.
What This Means For You (TABLE)
The AI Economics Have Reset
DeepSeek V4 is not a paper release—it is a restructuring of AI economics. For the past two years, frontier capability has been gated behind proprietary APIs with unpredictable token pricing and strict rate limits. V4 blows that gate open with a 1-trillion-parameter architecture that delivers millisecond response times, a 1-million-token context window, and 10× KV cache savings, all while matching or beating closed models on agentic tasks at roughly 27% of the compute cost. Whether you are a bootstrapped developer or a Fortune 500 architect, the model shifts the question from "Can we afford frontier AI?" to "Where do we deploy it first?"
| Your Role | DeepSeek V4 Advantage | The Hard Data | Strategic Payoff |
|---|---|---|---|
| Startup / Indie Developer | Open-source weights with proprietary-grade agentic performance | ~27% compute cost vs. closed alternatives | Build and scale AI products without Big Tech infrastructure bills |
| Enterprise Architect | Massive context + memory efficiency | 1M-token context, 10× KV cache savings | Ingest entire legal contracts, codebases, or conversation histories in a single pass |
| SaaS / Platform Builder | Real-time inference at trillion-parameter scale | 1T parameters, millisecond response times | Deliver sub-second user experiences that rival Big Tech APIs |
| Engineering Lead | Best-in-class coding and reasoning | "Significantly leads" open-source; near top-tier on world-knowledge benchmarks | Cut development cycles with AI-assisted code review and synthesis |
| Security-Focused CIO | On-premise deployment of open weights | mHC architecture, Engram Memory | Keep proprietary data in-house while running frontier-grade models |
Who Benefits Most—and How
If you lead AI at a startup, the cost line is the headline. Running agentic workflows on V4 costs roughly a quarter of what closed-model inference demands, which means margin-positive AI features become viable at much lower scale. For enterprise architects, the 1M context window is the game changer. Instead of chunking RFPs, health records, or multi-year Git histories into fragments, teams can pass entire corpuses to the model in one shot—while the 10× KV cache compression keeps GPU memory bills from exploding.
Platform engineers should note the combination of 1T parameters and millisecond latency. Historically, trillion-parameter models sat behind tier-1 API providers; V4 suggests you can self-host or fine-tune comparable horsepower without accepting second-tier response times. Engineering leads get a dedicated coding powerhouse: DeepSeek V4-Pro "significantly leads other open source models" and is only narrowly edged out by top-tier proprietary systems on world-knowledge tests. Finally, for CIOs navigating data-sovereignty rules, the open-weight release paired with DeepSeek’s mHC architecture and Engram Memory means the model can live entirely inside your VPC, not a vendor’s cloud.
What to Do Next
The practical next step is to audit your stack for provider lock-in. If your voice agents, chatbots, or copilots are hard-coded to a single proprietary endpoint, you are paying a premium for flexibility you no longer need. Consider these moves:
This is where modern communication infrastructure becomes critical. Platforms like CallMissed are already enabling businesses to deploy AI voice agents and WhatsApp chatbots through a multi-model API gateway that supports 300+ LLMs, letting teams switch between frontier open-source models like V4 and proprietary alternatives without code changes. As the open-source ecosystem accelerates, infrastructure that lets you swap models in real time isn't just convenient—it is the only way to capture the 73% cost advantage V4 represents and future-proof your AI stack against the next release cycle.
Frequently Asked Questions
Release Date and Benchmarks
What is DeepSeek V4 and when was it released?
How does DeepSeek V4 compare to GPT-4o and other proprietary models on agentic tasks?
Architecture and Long-Context Capabilities
What is the context window size of DeepSeek V4?
What are the key architectural innovations in DeepSeek V4?
Pricing and Commercial Integration
Is DeepSeek V4 open source and how much does it cost to use?
Can businesses integrate DeepSeek V4 into commercial communication platforms?
Conclusion
The Open-Source Efficiency Revolution
DeepSeek V4 represents more than an incremental upgrade—it marks an inflection point in how the industry balances performance, cost, and openness. In benchmark testing, DeepSeek V4-Pro significantly leads other open-source models and sits just behind top-tier proprietary systems in world knowledge tasks. Yet it achieves this while requiring only 27% of the compute cost compared to closed-source rivals on agentic workloads. The architecture itself is built for efficiency at scale:
This efficiency-first approach demonstrates that world-class AI does not require world-class infrastructure budgets.
What This Means for Builders and Businesses
For developers and enterprises, the V4 release collapses the traditional trade-off between capability and control. The model matches or beats several proprietary systems on agentic tasks, making it viable for:
As open-weight models close the gap with closed alternatives, the competitive moat shifts from raw model training to execution—how quickly organizations can integrate, fine-tune, and deploy these capabilities into real customer workflows.
This is where communication infrastructure becomes critical. Platforms like CallMissed are already enabling businesses to deploy production-ready AI voice agents and WhatsApp chatbots over multi-model LLM inference. With support for switching across 300+ models, solutions like CallMissed allow engineering teams to route traffic to high-efficiency architectures such as DeepSeek V4 without refactoring codebases, ensuring businesses capture the model's ultra-low pricing and long-context advantages the moment weights are available. For multilingual markets, integrating these open-source capabilities with Speech-to-Text and Text-to-Speech APIs covering 22 Indian languages further democratizes access to frontier automation.
Looking Ahead: The New Normal for AI
DeepSeek’s latest release arrives against a backdrop of tightening export controls and intensifying geopolitical competition—conditions the company has turned into an innovation constraint rather than a limitation. By proving that sparse attention, memory-efficient caching, and hybrid architectures can deliver frontier performance under hardware restrictions, V4 sets a template for the next wave of global AI development.
The ripple effects will be immediate. Pricing pressure on proprietary APIs will accelerate. The definition of “state-of-the-art” will increasingly include cost-per-token and context-length efficiency, not just leaderboard accuracy. And the open-source ecosystem will solidify its role as the default substrate for commercial AI deployment.
One year after stirring the industry with its cost-efficient R1 models, DeepSeek has returned to reset expectations again. V4 makes clear that the future belongs not to the biggest budget, but to the most creative architecture—and that future is already open source.
Conclusion
DeepSeek V4 marks another inflection point in the open-source AI movement, proving that world-class performance no longer requires proprietary gatekeeping or massive capital expenditure. As the dust settles on this release, a few clear lessons emerge for developers, enterprises, and AI strategists:
Looking ahead, the industry should watch how Western labs respond to this efficiency pressure, whether export controls accelerate alternative hardware ecosystems, and how agentic AI built on models like V4 will reshape enterprise automation. The next battleground won't be parameter count alone—it will be inference cost, long-context reliability, and real-world agent execution.
For businesses and developers ready to operationalize these advances, the infrastructure layer matters as much as the model itself. Platforms like CallMissed are already enabling teams to deploy production-ready AI voice agents and multilingual chatbots that can leverage cutting-edge LLMs for real customer interactions. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
As open-source models continue to erase the moat of closed systems, one question remains: will your organization build on these democratized foundations, or wait until the pricing—and competitive landscape—has already been rewritten?


