The GPU Scarcity Story: H100, H200, and B200

The 2026 GPU supply picture — H100 softening, H200 plentiful, B200 ramping — and a practical decision matrix for what to rent or buy for AI workloads.
"GPU shortage" was the defining infrastructure story of 2023 and 2024. By 2026 the story has shifted — but it has not gone away. Hopper-generation supply has loosened, Blackwell is ramping but constrained, and the gap between "what you can buy on a credit card" and "what you can buy with a multi-year commit" has only widened. Here is the picture as of mid-2026.
H100: from scarce to soft
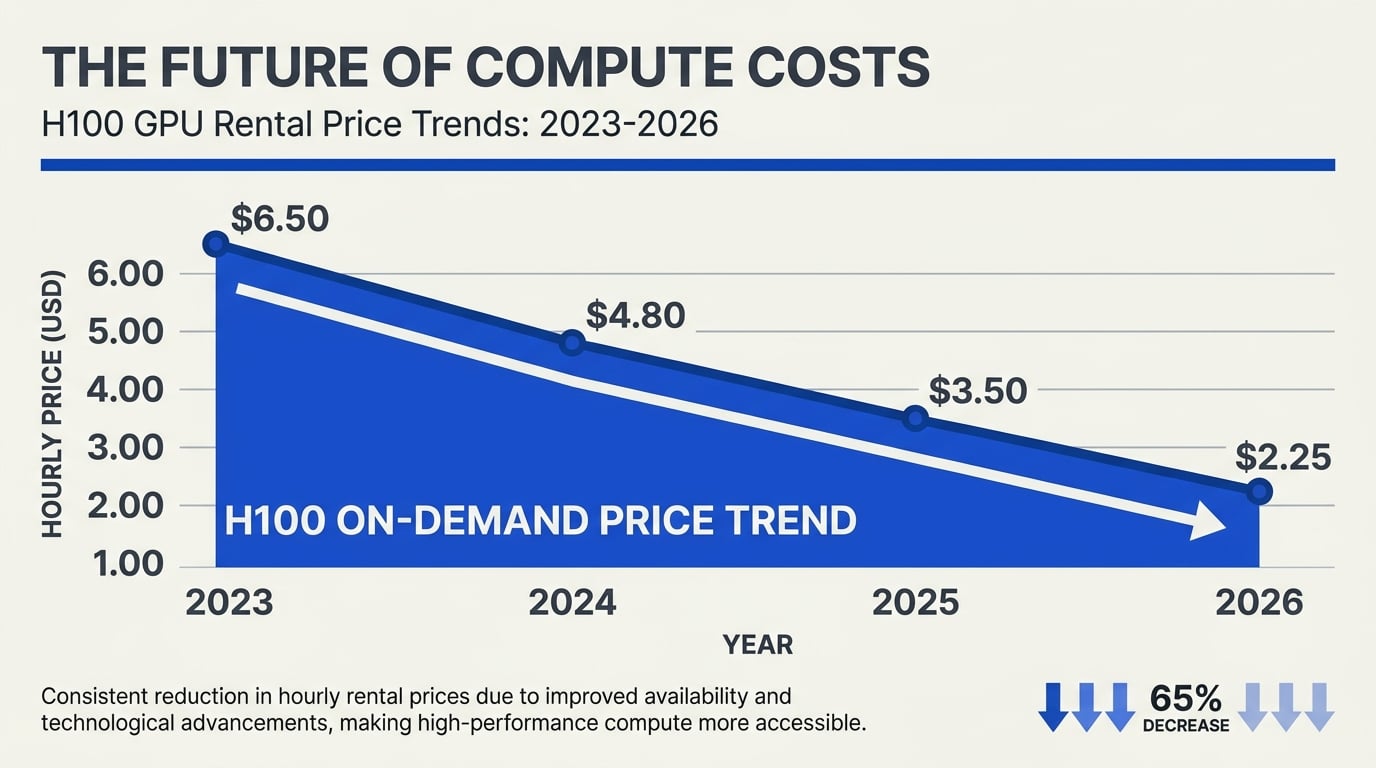
The H100, NVIDIA's 2022-launched Hopper flagship, drove most of the 2023–2024 scarcity headlines. By 2026 it is widely available across cloud providers, with on-demand rates falling steadily as Blackwell capacity comes online. Spot and preemptible H100 pricing has slid first; on-demand list prices have followed. (Spheron blog) [Unverified — directional]
For most production inference workloads under ~70B parameters, H100 is now the value tier. It is plentiful, well-supported by every framework, and prices keep softening.
H200: the quiet workhorse
The H200 is essentially an H100 die paired with 141 GB of HBM3e memory and higher memory bandwidth. (NVIDIA H200 page) For LLM inference — which is bandwidth-bound, not compute-bound — the H200's larger HBM is often more useful than B200's raw FLOPS for models in the 70B–200B range.
H200 supply caught up faster than H100 ever did, and as B200 ramps the H200 market is softening too. For a team that wants Hopper headroom without B200 lead times, H200 is the practical pick in 2026. [Inference]
B200: shipping but constrained

The Blackwell B200 began shipping in late 2025 and through 2026 hyperscalers (AWS, GCP, Azure, Oracle) are rolling out instances. (gpu.fm guide)
The mechanical reasons B200 is hard to get:
- Dual-die GB100 design — two large dies on TSMC's 4NP node, each with non-trivial yield drop on a large reticle.
- CoWoS-L packaging capacity at TSMC is the bottleneck, not just wafers.
- HBM3e supply (SK Hynix dominant, Micron and Samsung qualifying) is a separate constraint.
One reported figure — an estimated 3.6 million unit backlog as of April 2026 — captures the gap between order book and shipments. (gpu.fm) [Unverified — single-source estimate]
For builders, the practical implication: cloud rental is the only realistic path to B200 inside a 30–60 day window. Buying hardware through OEMs (Supermicro, Dell, HPE) is a multi-quarter commitment, often gated by minimum-purchase agreements.
What builders actually buy in 2026
[Inference] Based on cloud-provider pricing pages and reported deal patterns:
| Tier | Workload | Practical pick |
|---|---|---|
| Inference, ≤70B model | Most production serving | H100 (value) or H200 (memory headroom) |
| Inference, 70B–200B | Larger open models, MoE | H200 or B200 (when available) |
| Inference, 200B+ frontier | Self-hosted Llama-class | B200 / GB200 NVL72 (rented) |
| Training, fine-tune | LoRA, small SFT | H100 or A100 — cheap and plentiful |
| Training, frontier | Pre-training new models | B200 / GB200 — multi-year commits |
Alternatives: AMD, Trainium, TPU
The "NVIDIA-only" world is loosening at the edges:
- AMD MI300X / MI325X — 192–256 GB HBM, attractive for very-large-model inference. ROCm support has matured but ecosystem is still narrower than CUDA.
- AWS Trainium 2 / Inferentia 2 — competitive on $/inference for Bedrock-served workloads, especially Anthropic models on Trainium clusters.
- Google TPU v5p / v5e / Trillium — strong for Gemini-class inference, available via Vertex AI.
- Groq, Cerebras, SambaNova — specialized inference hardware. Groq leads on absolute tokens-per-second for select models. [Unverified]
For most teams in 2026, NVIDIA is still the default. The alternatives are credible enough that single-vendor lock-in is the more interesting risk than "alternatives don't work."
Practical advice
- Don't chase Blackwell unless you need it. H100 and H200 cover the bulk of production inference, and they are cheaper per token than B200 today even where B200 is available.
- Spot tier is the cost lever. Spot/preemptible H100 is 40–60% off on-demand on most clouds. If your workload tolerates restart, it is the highest-leverage saving available.
- Reserve only for predictable load. 1- and 3-year reservations get 30–60% off, but on a workload that may shift to a different hardware tier in 12 months you can over-commit yourself into a Blackwell-shaped problem.
- Watch HBM, not chips. The actual scarcity in 2026 is not silicon — it is HBM3e packaging. That is what gates B200 supply, and it is what will gate B100 / H200 prices recovering. [Inference]
Bottom line
The 2023 narrative — "you cannot get GPUs" — has become 2026's "you cannot get the newest GPUs at retail timelines." For most inference workloads, that does not matter. Hopper-tier is plentiful and cheap-er, and Blackwell rental is widely available even if Blackwell purchase is not. Plan capacity around what you can actually buy in your decision window, not around the press release.
Frequently Asked Questions
Is the H100 still worth buying in 2026?
How long is the wait for B200?
Should I consider AMD or AWS Trainium as an alternative?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.